2026/6/1 6:53:19
网站建设
项目流程
大连微网站开发,济南网站建设排名,怎么建网站站点,网站建设手机站张量的基本运算
add() 加
sub(),减 -
mul(),乘 *
div(),除 /
neg() 取负 -
add_(), sub_(), mul_(), div_(), neg_() # 功能同上#xff0c;但会修改原有数据, 功能类似pandas中的inplaceTrue按元素相乘运算
元素级乘法, 对应位置的元素进行相乘
两个张量形状相同
mul()/*
…张量的基本运算add() 加 sub(),减 -mul(),乘 *div(),除 /neg() 取负 -add_(), sub_(), mul_(), div_(), neg_() # 功能同上但会修改原有数据, 功能类似pandas中的inplaceTrue按元素相乘运算元素级乘法, 对应位置的元素进行相乘两个张量形状相同mul()/*矩阵乘法运算行*列, 行每个数据和列每个数据相乘求和规则: (n, m) * (m, p) (n, p)/torch.matmul()张量运算函数min/max/mean/sum(dim)不设置dim参数, 对所有元素进行计算设置dim参数, 对应维度元素进行计算sqrt()/**0.5平方根, 开根号log()/log2()/log10()/log1p()对数pow()/**幂次方 x^nexp()指数 e^x张量索引操作作用根据索引获取对应位置的数据tensor[0轴下标, 1轴下标, ...]从左到右从0开始, 0-第一个数据从右到左从-1开始, -1-最后一个数据下标取值tensor[0]-0轴第一个数据tensor[:, 0] -1轴第一个数据列表取值tensor[[0,1], [2,4]]-0轴第1个1轴第3个值, 0轴第2个1轴第5个值范围取值(切片)tensor[起始索引:结束索引:步长,...]布尔取值tensor[:, 0]10判断1轴第1组数据大于10-返回T/Ftensor[tensor[:, 0]10]获取True对应的0轴数据多维索引指定每个维度/轴的索引, tensor[1,2,3]张量形状操作tensor.reshape(shape)在保证数据不变的前提下, 修改连续和非连续张量形状修改前后的张量元素个数一致-1:自动计算tensor.squeeze(dim)删除长度为1的维度/轴, 可以通过dim指定删除维度tensor.unsqueeze(dim)在指定维度上增加维度值1tensor.view(shape)修改连续张量的形状, 操作等同于reshapetensor.contiguous()转换成连续张量tensor.is_contiguous()判断张量是否连续tensor.transpose(dim0, dim1)交换指定两个维度的数据参数值是维度下标值tensor.permute(dims())交换任意维度的数据参数值是维度下标值张量拼接操作torch.cat([t1, t2, ...], dim)在指定维度上对张量进行拼接其他维度值相同, 不改变新张量的维度指定维度的维度值相加torch.stack([t1, t2, ...], dim)在指定维度上对张量进行堆叠其他维度值相同, 新张量在指定维度新增维度指定维度的维度值就是张量个数所拼接的两个张量的shape必须相同循环自动微分模块步骤1. 定义变量w torch.tensor(10,requires_gradTrue,dtypetorch.float)定义loss变量表示损失变量利用梯度下降法循坏迭代指定次数求最优解3.1 正向传播3.2 梯度清零因为系统会将梯度自动叠加3.3 反向传播3.4 梯度更新自动微分模块入门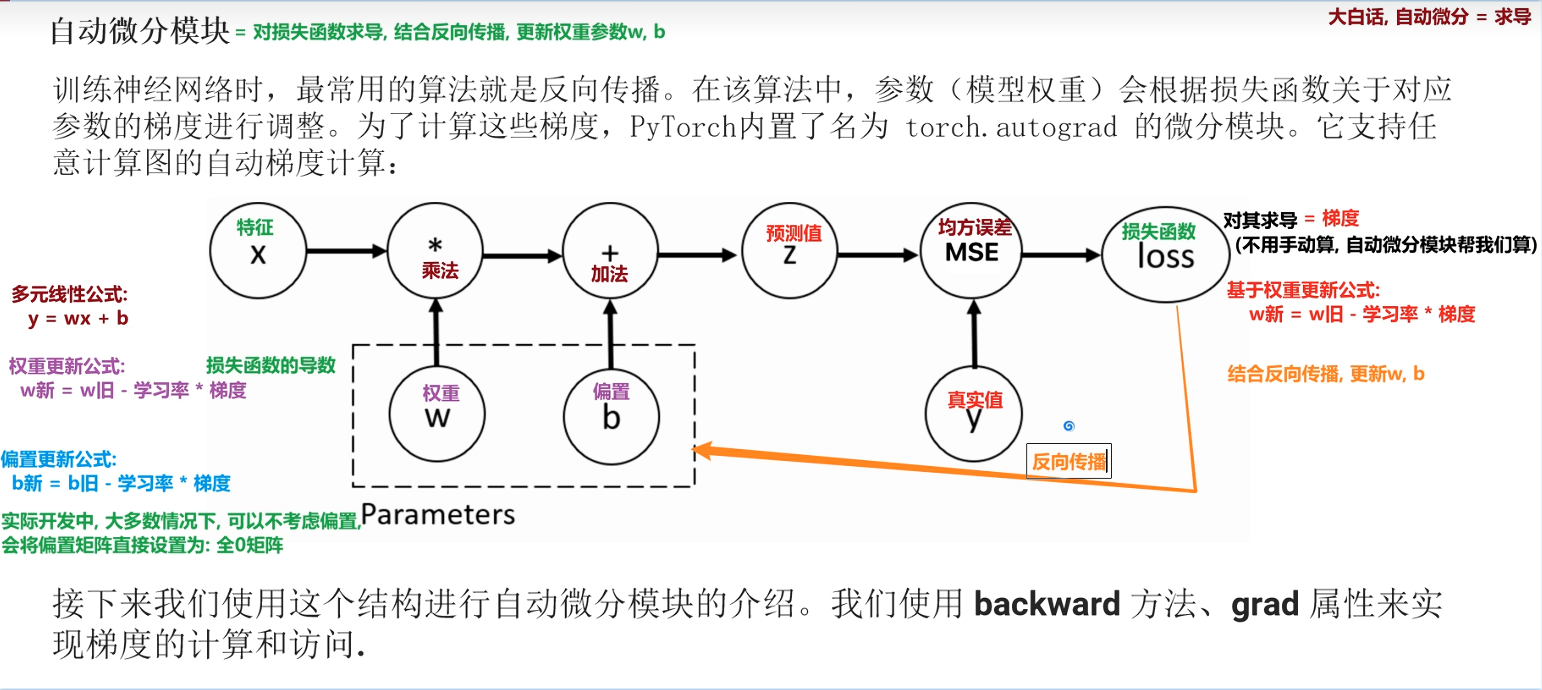反向传播基于预测和真实可以得出误差从而得到损失函数的结果针对损失函数的结果进行求导就可以得到本次的梯度值为多少有了梯度值之后就可以反向更新w和b会让第二轮的结果更加精准从而一步步使得值达到最优。自动微分模块对损失函数求导结合反向传播更新权重参数wb多元线性公式 ywxb权重更新公式:w新w旧-学习率*梯度偏置更新公式b新b旧-学习率*梯度实际开发中大多是情况下不考虑偏置会将偏置矩阵直接设置为全0矩阵只有标量才能对向量求导pytorch框架_模拟线性回归detch()函数功能一个张量 一旦开启了梯度计算/自动微分就无法转为 numpy对象需要通过detach()函数来解决 案例 演示 detach()函数功能解决自动微分的弊端 回顾 自动微分求导 基于损失函数 计算梯度 结合权重更新公式w新w旧-学习率*梯度来更新权重的 问题 一个张量 一旦开启了梯度计算/自动微分 就无法转为 numpy对象需要通过detach()函数来解决 需要掌握 n1 t1.detach().numpy() 使得自动微分的张量能够转化为numpy类型 importtorchimportnumpyasnpimportmatplotlib.pyplotaspltimportmatplotlib matplotlib.use(TKAgg)plt.rcParams[font.sans-serif][SimHei]# 用来正常显示中文标签plt.rcParams[axes.unicode_minus]False# 用来正常显示负号#设置设备devicetorch.device(cudaiftorch.cuda.is_available()elsecpu)# 1.定义张量# 参数1数据参数2是否自动微分/求导/梯度计算参数3数据类型t1torch.tensor([1,2,3],requires_gradTrue,dtypetorch.float32)print(ft1:{t1}, type:{type(t1)}, requires_grad:{t1.requires_grad})# 2. 张量 转 numpy对象# n1 t1.numpy()# print(fn1: {n1}, type: {type(n1)})# 3.使用 detach() 函数, 拷贝一份张量t2t1.detach()print(ft2:{t2}, type:{type(t2)}, requires_grad:{t2.requires_grad})# 4.测试 t1, t2 是否共享内存t1.data[0]100print(ft1:{t1}, type:{type(t1)}, requires_grad:{t1.requires_grad})print(ft2:{t2}, type:{type(t2)}, requires_grad:{t2.requires_grad})## # 5. t2 - numpy对象# n1 t2.numpy()# print(fn1: {n1}, type: {type(n1)})n1t1.detach().numpy()print(fn1:{n1}, type:{type(n1)})自动微分真实应用场景演示 自动微分的真实应用场景工作流1.前向传播计算 预测值z 2.基于loss_fn损失函数结合 预测值z 和 真实值y, 来计算损失值loss 3.自动微分反向传播loss.backward(),过程中自动计算loss对模型参数w, b的梯度/导数 4.更新权重梯度下降法w新 w旧 - 学习率 * 梯度importtorch#定义 x 表示:特征输入数据假设2行5列全1矩阵xtorch.ones(2,5)print(fx:{x}, shape:{x.shape})# 2.定义yytorch.zeros(2,3)print(fy:{y}, shape:{y.shape})# 3.初始化模型参数 权重w, 偏置b, x w bwtorch.randn(5,3,requires_gradTrue,dtypetorch.float32)btorch.randn(3,requires_gradTrue,dtypetorch.float32)print(fw:{w}, shape:{w.shape})print(fb:{b}, shape:{b.shape})# 4.前向传播计算 预测值zztorch.matmul(x,w)bprint(fz:{z}, shape:{z.shape})#5.计算损失criteriontorch.nn.MSELoss()losscriterion(z,y)print(floss:{loss})# 6.反向传播演示自动微分计算梯度loss对w, b的梯度# #如果loss不是一个值的话需要改为# loss.sum().backward()loss.backward()print(f梯度w.grad:{w.grad})print(f梯度b.grad:{b.grad})# 后续就是梯度下降法来更新模型参数w, bpytorch框架_模拟线性回归工作流1.准备训练集数据构建数据加载器张量 - 数据集对象TensorDataset - 数据加载器DataLoader 2.构建要使用的模型 3.设置损失函数和优化器 4.模型训练 6.可视化损失函数曲线拟合曲线# 导入相关模块importtorch# numpy对象 - 张量Tensor - 数据集对象Dataset - 数据加载器DataLoader -分批次获取流程fromtorch.utils.dataimportTensorDataset# 构造数据集对象fromtorch.utils.dataimportDataLoader# 数据加载器分批次加载数据方便模型按批次训练fromtorchimportnn# nn模块中有平方损失函数和假设函数线性网络层fromtorchimportoptim# optim模块中有优化器函数fromsklearn.datasetsimportmake_regression# 创建线性回归模型数据集importmatplotlib.pyplotasplt# 绘图importmatplotlib matplotlib.use(TKAgg)plt.rcParams[font.sans-serif][SimHei]# 用来正常显示中文标签plt.rcParams[axes.unicode_minus]False# 用来正常显示负号# 1.定义函数构造数据集defcreate_dataset():# 创建数据集对象x,y,coefmake_regression(n_samples100,# 样本数量,100n_features1,# 特征数量,1noise10,# 噪声coefTrue,# 是否返回系数bias14.5,# 偏置random_state24,)# 转化为张量xtorch.tensor(x,dtypetorch.float32)ytorch.tensor(y,dtypetorch.float32)# 返回结果returnx,y,coef#2.定义函数表示模型训练deftrain(x,y,coef):#创建数据集对象 把tensor-数据集 -数据加载器datasetTensorDataset(x,y)#2.创建数据加载器对象#参1数据集对象 参2批次大小 参3 是否打乱数据训练集打乱测试集不打乱dataloaderDataLoader(dataset,batch_size16,shuffleTrue)#3.创建初始的 线性回归模型#参1输入特征未付参2 输出特征维度modelnn.Linear(1,1)#4.创建损失函数对象criterionnn.MSELoss()#5.创建优化器对象#参1 模型参数 参2 学习率optimizeroptim.SGD(model.parameters(),lr0.01)#6.具体的训练过程#6.1定义变量 分别表示 训练轮数 每轮的平均损失值 训练总损失 训练的样本epochs,loss_list,total_loss,total_sample100,[],0.0,0#6.2开始训练按轮训练forepochinrange(epochs):#epochs 的值012,....99#6.3 每轮是分批次 训练的所以从 数据记载器中 获取 批次数据fortrain_x,train_yindataloader:#7批(16,16,16,16,16,16,4)#6.4 模型预测y_predmodel(train_x)#6.5计算(每批的平均值)losscriterion(y_pred,train_y.reshape(-1,1))#-1 自动计算#6.6计算总损失 和样本批次数total_lossloss.item()total_sample1#6.7梯度清零 反向传播 梯度更新optimizer.zero_grad()#梯度清零loss.backward()#反向传播计算梯度optimizer.step()#梯度更新#6.8把本轮的(平均) 损失值添加到列表中loss_list.append(total_loss/total_sample)print(f第{epoch1}轮平均损失值:{total_loss/total_sample})#7.打印(最终的)训练结果print(f{epochs}轮的平均损失分别为:{loss_list})print(f模型参数,权重:{model.weight},偏置:{model.bias})#8.绘制损失曲线# 100轮 每轮的平均损失值plt.plot(range(epochs),loss_list)plt.title(损失值曲线变化图)plt.grid()#绘制网格线plt.show()#9.绘制预测值和真实值的关系#9.1绘制样本点分布情况plt.scatter(x,y)#9.2绘制训练模型的预测值#x:100个样本点的特征y_predtorch.tensor(data[v*model.weightmodel.biasforvinx])#9.3 计算真实值y_truetorch.tensor(data[v*coef14.5forvinx])#9.4绘制预测值 和真实值的 折线图plt.plot(x,y_pred,colorred,label预测值)plt.plot(x,y_true,colorgreen,label真实值)#9.5图例 网格plt.legend()plt.grid()#9.6显示图像plt.show()if__name____main__:x,y,coefcreate_dataset()train(x,y,coef)